
Google introduces ‘SoundStorm,’ an AI tool for creating human-like voiceovers using discrete conditioning tokens
SoundStorm provides users with control over various aspects of the generated audio, including the spoken content through transcripts, speaker voices using short voice prompts, and speaker turns via transcript annotations.
 artificial intelligence
artificial intelligence
New Delhi, UPDATED: Jul 17, 2023 17:01 IST
Highlights
- SoundStorm is capable of creating human-like voice overs
- It improves acoustic modelling with a faster parallel decoding method
- It outperforms AudioLM in speed and consistency for audio samples
Google recently unveiled a new audio creation model called ‘SoundStorm: Efficient Parallel Audio Generation’ which was announced in a paper published by the company a few weeks ago. This model presents an innovative approach to addressing the challenge of generating lengthy audio token sequences.
SoundStorm is an advanced audio AI model known for generating natural and high-quality dialogues. The results are so accurate that they can be passed off as real human conversations. The tool provides users with control over various aspects of the generated audio, including the spoken content through transcripts, speaker voices using short voice prompts, and speaker turns via transcript annotations.
It incorporates two key components: a specially designed architecture for audio tokens (allows language servers to provide additional information based on the language server's knowledge) produced by the SoundStream neural codec and a decoding scheme inspired by MaskGIT, a method used for image generation that has been adapted to operate on audio tokens.
Features of SoundStorm
In addition, the paper released showcases that when SoundStorm is combined with the text-to-semantic modelling stage of SPEAR-TTS (a multi-speaker text-to-speech system), it enables the synthesis of natural and high-quality dialogues.
advertisement
This integration offers control over the spoken content using transcripts, the selection of speaker voices through short voice prompts, and managing speaker turns through transcript annotations. The paper provides examples that demonstrate the effectiveness of SoundStorm and its collaboration with SPEAR-TTS in generating realistic and convincing dialogues.
Compared to the autoregressive decoding approach used in a model called AudioLM, SoundStorm achieves parallel generation of tokens, leading to a remarkable 100-fold reduction in inference time for long sequences. Despite this increased efficiency, SoundStorm maintains high audio quality and also enhances consistency in voice conditions.
Applications of SoundStorm
Here's a closer look at the applications of Sound storm.
Enhanced Audio Generation: SoundStorm can revolutionise audio production by generating highly realistic and high-quality audio content. It has the potential to improve the efficiency and creativity of sound design, music production, voiceovers, and other audio-related fields.
Entertainment Industry: The entertainment industry can benefit from SoundStorm's capabilities. It can be used in film, television, and video game production to create immersive soundscapes, generate realistic dialogue, or even replicate the voices of actors for various purposes.
Voiceovers: SoundStorm can contribute to the development of more advanced and natural-sounding virtual assistants, voiceover services, and speech synthesis technologies. This can enhance user experiences and make human-computer interactions more engaging.
advertisement
SoundStorm in comparison to AudioLM
In their previous work on AudioLM, the researchers presented a two-step process for audio generation involving semantic modelling and acoustic modelling. However, in SoundStorm, the focus was specifically on improving the acoustic modelling step by replacing the slower autoregressive decoding with a faster parallel decoding method.
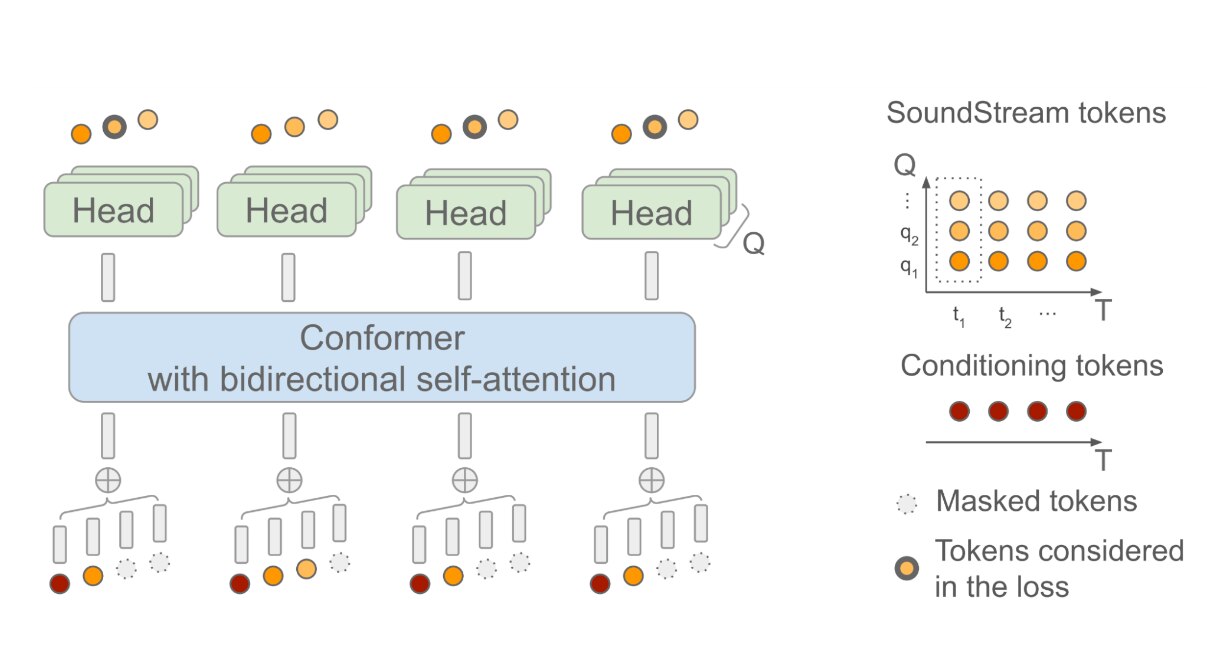
Furthermore, SoundStorm utilised a bidirectional attention-based conformer architecture that combines convolutions with a Transformer. This architecture allowed for capturing both local and global structures in the sequence of tokens. The model was trained to predict audio tokens produced by SoundStream, given a sequence of semantic tokens generated by AudioLM.
During inference, SoundStorm employed a masked token-filling approach over multiple iterations. It started with coarse tokens at the lowest RVQ level and progressively filled in finer tokens until reaching the highest level. This process enabled the fast generation of audio.
Two key factors contributed to the fast-generation capability of SoundStorm. Firstly, tokens were predicted in parallel within a single iteration at each RVQ level. Secondly, the model architecture was designed to minimise the computational complexity impact with increasing levels of token generation.
advertisement
Compared to AudioLM, SoundStorm demonstrated a significant improvement in speed, being two orders of magnitude faster. It also achieved better consistency over time when generating lengthy audio samples.
Implications of SoundStorm
SoundStorm has various implications in the field of audio synthesis. While it offers significant advancements in audio generation, it's essential to consider the potential challenges and risks associated with the technology, including its potential use in creating deepfake tools.
The misuse of SoundStorm or any similar advanced audio generation technology can have serious consequences. Here are some potential misuse scenarios.
Deepfakes and manipulated audio: SoundStorm could be used to create convincing fake audio recordings or impersonations. This can be exploited to spread misinformation, manipulate public opinion, or deceive individuals by making them believe someone said something they did not.
Voice fraud: SoundStorm-powered tools could be misused to create fraudulent voice samples for unauthorised access to systems or voice-based authentication.
Audio blackmail: The ability to generate realistic audio could be misused for blackmailing purposes. Threat actors can create false audio evidence or manipulate existing recordings to extract money or favors.
Mitigating the Misuse
To address the potential misuse of SoundStorm and similar technologies, several measures can be taken:
advertisement
Public awareness and education: Educate the public about the existence of audio manipulation technologies, their potential risks, and how to critically evaluate audio content to identify potential manipulations.
Legal and ethical guidelines: Establish clear legal frameworks and ethical guidelines regarding the use of synthesised audio content, particularly in sensitive contexts such as legal proceedings or public discourse.
Responsible deployment: Technology developers, including Google AI, should implement safeguards and monitoring mechanisms to prevent the misuse of SoundStorm within their platforms and services.
By being proactive in addressing the risks and implementing appropriate safeguards, it is possible to mitigate the potential misuse of SoundStorm and ensure responsible use of this technology.
Published on: Jul 17, 2023 14:34 ISTPosted by: samira siddiqui, Jul 17, 2023 14:34 IST
IN THIS STORY
COMMENTS 0